Transaction
이 개념에 대한 질문은 자주 나오는거 같다. 다른 회사 필기 시험에서도 봤다.
트랜젝션이란?
트랜잭션(Transaction 이하 트랜잭션)이란, 데이터베이스의 상태를 변화시키기 해서 수행하는 작업의 단위를 뜻한다.
데이터베이스의 상태를 변화시킨다는 것은 무얼 의미하는 것일까?
간단하게 말해서 아래의 질의어(SQL)를 이용하여 데이터베이스를 접근 하는 것을 의미한다.
- SELECT
- INSERT
- DELETE
- UPDATE
착각하지 말아야 할 것은, 작업의 단위는 질의어 한문장이 아니라는 점이다.
작업단위는 많은 질의어 명령문들을 사람이 정하는 기준에 따라 정하는 것을 의미한다.
출처: https://mommoo.tistory.com/62 [개발자로 홀로 서기]
트래젝션의 종류 ACID
- 원자성 (Atomicity) : 원자성은 트랜잭션이 데이터베이스에 모두 반영되던가, 아니면 전혀 반영되지 않아야 한다는 것이다. 트랜잭션 내의 모든 명령은 반드시 완벽히 수행되어야 하며, 모두가 완벽히 수행되지 않고 어느 하나라도 오류가 발생하면 트랜잭션 전부가 취소되어야 한다.
- 일관성 (Consistency) : 트랜잭션이 성공적으로 완료되면 일관적인 DB상태를 유지하는 것을 말합니다. 여기서 일관성이란, 송금 예제의 경우 데이터 타입이 정수형인데, 갑자기 문자열이 되지 않는 등의 변화를 말합니다.
- 독립성 (Isolation) : 어느 하나의 트래잭션이라도 다른 트랜잭션의 연산을 끼어들 수 없다. 즉 트랜잭션끼리는 서로를 간섭할 수 없습니다.
- 지속성 (Durability) : 트랜잭션이 성공적으로 완료됬을 경우, 결과는 영구적으로 반영되어야 한다는 점이다. 커밋하면 현재 상태는 영원히 보장됩니다.
출처: https://mommoo.tistory.com/62 [개발자로 홀로 서기] 그리고 다른것들...
원자성의 보장
트랜잭션에서 원자성은 수행하고 있는 트랜잭션에 의해 변경된 내역을 유지하면서, 이전에 commit된 상태를 임시 영역에 따로 저장함으로써 보장합니다.
즉, 현재 수행하고 있는 트랜잭션에서 오류가 발생하면 현재 내역을 날려버리고 임시 영역에 저장했던 상태로 rollback 합니다.
이전 데이터들이 임시로 저장되는 영역을 롤백 세그먼트(rollback segment)라고 하며,
현재 수행하고 있는 트랜잭션에 의해 새롭게 변경되는 내역을 테이터베이스 테이블이라고 합니다.
다시 말하면, 트랜잭션의 원자성은 롤백 세그먼트에 의해 보장된다고 할 수 있습니다.
그런데 오류가 발생하면 rollback을 하는데, 트랜잭션의 길이가 길어지면 어떻게 될까요?
확실하게 오류가 발생하지 않는 부분도 다시 처음부터 작업을 수행해야 합니다.
따라서 확실한 부분에 대해서는 rollback이 되지 않도록 중간 저장 지점인 save point를 지정할 수 있습니다.
save point를 지정하면 rollback 할 때 save point 이전은 확실하다 간주하고 그 이후부터 진행하게 됩니다.

트랜잭션에서 일관성은 트랜잭션 수행 전, 후에 데이터 모델의 모든 제약 조건(기본키, 외래키, 도메인, 도메인 제약조건 등)을 만족하는 것을 통해 보장합니다.
예를 들어, Movie와 Video 테이블이 있을 때 Video 테이블에 Movie 테이블의 primary key인 movie_id가 외래키로 존재한다고 가정하겠습니다.
만약 movie_id의 제약조건이 Movie 테이블에서 변경되면, Video 테이블에서도 movie_id 가 변경되어야 합니다.
한 쪽의 테이블에만 데이터 변경사항이 이루어지면 안되는 것이죠.
그렇다면 어떻게 트랜잭션은 일관성을 보장할까요?
어떤 이벤트와 조건이 발생했을 때, 트리거( Trigger )를 통해 보장합니다.
트리거는 "방아쇠"인데, 데이터베이스 시스템이 자동적으로 수행할 동작을 명시하는데 사용됩니다.
어떤 행위의 시작을 알리는 것이죠.

위의 코드는 트리거가 호출되면, 수행할 질의들을 트리거로 생성해서 작성한 코드입니다.
create는 트리거를 생성하는 코드이고, after는 트리거가 실행되기 위한 event를 나타냅니다.
근데 그래서 트리거로 일관성을 보장한다는거 같은데, 트리거로 일관성을 어떻게 보장한다는 거지? 트리거가 뭔지는 알겠는데 일관성이랑 무슨 상관인지 모르겠다.
트랜잭션이 고립성을 보장하는 방법에 대해 이해하기 위해서는 병행 트랜잭션에 대해 먼저 알아야 합니다.
1) 병행 처리 ( concurrent processing )
CPU가 여러 프로세스를 처리하는 것처럼, 트랜잭션에 정해진 시간을 할당해서 작업을 하다가 부여된 시간이 끝나면 다른 트랜잭션을 실행하는 이런 방식으로 트랜잭션들을 조금씩 처리하는 것을 말합니다.
그런데 이렇게 되면 많은 트랜잭션들이 조금씩 처리되는 과정에서 공통된 데이터를 조작하게 되는데, 이 경우 데이터가 혼란스러워 질 수 있습니다.
예를 들어, A 트랜잭션에서 x라는 데이터를 100으로 설정한 후 시간이 만료되어 B 트랜잭션으로 넘어갔다고 가정해보겠습니다.
B 트랜잭션에서는 x 데이터에 -50 연산을 해서 저장을 했을때, 시간이 만료되어 다시 A 트랜잭션이 실행될 경우 x 데이터의 값은 50이 됩니다.
이렇게 트랜잭션이 조금씩 수행될 때, 공통된 데이터가 다른 트랜잭션에 의해 방해되면 안됩니다.
이와 같이 트랜잭션의 간섭이 일어날 경우 갱신분실, 오손판독, 반복불가능, 팬텀문제 등 여러 문제점들이 발생합니다.
2) 고립성 보장
병행처리 과정에서 트랜잭션의 고립성이 왜 보장되어야 하는지를 알게되었습니다.
그러면 고립성을 어떻게 보장할 수 있을까요?
OS의 세마포어(semaphore)와 비슷한 개념으로 lock & excute unlock을 통해 고립성을 보장할 수 있습니다.
즉, 데이터를 읽거나 쓸 때는 문을 잠궈서 다른 트랜잭션이 접근하지 못하도록 고립성을 보장하고, 수행을 마치면 unlock을 통해 데이터를 다른 트랜잭션이 접근할 수 있도록 허용하는 방식입니다.
트랜잭션에서는 데이터를 읽을 때, 여러 트랜잭션이 읽을 수는 있도록 허용하는 shared_lock을 합니다.
즉, shared_lock은 데이터 쓰기를 허용하지 않고 오직 읽기만 허용합니다.
또한 데이터를 쓸 때는 다른 트랜잭션이 읽을 수도 쓸 수도 없도록 하는 exclusive_lock을 사용합니다.
그리고 읽기, 쓰기 작업이 끝나면 unlock을 통해 다른 트랜잭션이 lock을 할 수 있도록 데이터에 대한 잠금(lock)을 풀어줍니다.
그런데 lock과 unlock을 잘못 사용하면 데드락(deadlock)상태에 빠질 수 있습니다.
모든 트랜잭션이 아무것도 수행할 수 없는 상태가 되는 것이죠.

3) 2PL 프로토콜 ( 2 Phase Locking protocol )
당연히 데드락이 걸리면 안되므로, 어떤 규칙에 의해서 고립성을 보장해야 한다는 2PL 프로토콜이 연구되었습니다.
2PL 프로토콜이란 여러 트랜잭션이 공유하고 있는 데이터에 동시에 접근할 수 없도록 하기위한 목적을 가진 프로토콜입니다.
이름 그대로 2가지 단계의 locking이 존재하는데, 한 가지는 growing phase이고 다른 한 가지는 shrinking phase입니다.
상승 단계란 read_lock , write_lock을 의미하고, 하강 단계란 unlock를 의미합니다.
2PL 프로토콜은 상승 단계와 하강 단계와 섞이면 안된다는 것을 의미합니다.
즉, lock과 unlock이 번갈아 수행되지 않고 lock이 쭉 수행된 후에 unlock이 쭉 수행되어야 한다는 것이 이 프로토콜입니다.

정리하면 성능을 위해 병행처리를 해야하는데, 트랜잭션의 고립성을 보장하기 위해서는 2PL을 사용해야 한다는 것입니다. ( Serializable Schedule )
참고로 locking을 하는 방법에도 두 가지가 있습니다.
- 보수적 locking ( conservative locking )
- 트랜잭션이 시작되면 모든 lock을 얻는 방식으로서, 데드락이 발생하지 않지만 병행성이 좋지 못함
- 엄격한 locking ( strict locking )
- 트랜잭션이 commit을 만날 때까지 lock을 갖고 있다가 commit을 만날때 unlock을 하는 방식으로 데드락이 발생하지만 병행성이 좋음
- 일반적으로 병행성이 좋은 strict 방식을 사용합니다.
음 락에 대한 부분은 제대로 이해가 안됐다. 왜 투 페이스 락이 있는 건지도 모르겟다;;
뷰 ( View )
DB 객체를 보호하는 방법으로 사용자에게 권한(privilage)을 부여하는 방법이 있습니다.
이와 달리, 뷰 테이블( 원본 테이블을 그대로 두고, 노출하고 싶은 필요한 정보들만 모아서 가상 테이블 )을 만들어 보호하는 방법이 있습니다.
즉, 사용자가 보는 테이블은 실제 테이블이 아닌 가상의 테이블이므로, 원본 테이블에 영향을 주지 않으므로 DB객체를 보호할 수 있습니다.

위의 쿼리는 VIEW_SAMPLE라는 이름의 뷰를 생성하는 쿼리입니다.
원본 테이블( base table )은 Student이고, VIEW_SAMPLE은 stu_no와 name만을 Attribute로 갖는 가상의 테이블이죠.
이와 같이 보여주고 싶은 Attribute만 선택해서 뷰를 만들 수 있습니다.
뷰는 가상의 테이블이지만, 일반적인 테이블처럼 쿼리를 수행할 수 있습니다.
단, SELECT 쿼리에 대해서는 제약조건이 없지만 UPDATE, DELETE, INSERT에 대해서는 제약조건이 있습니다.
여기서 말하는 제약조건이란, 뷰의 Attribute에는 base table의 primary key가 존재해야 한다는 것입니다.
그런데 사실 뷰의 목적은 데이터 조회에 있습니다.
따라서 뷰의 데이터를 조회할 때 일반 테이블처럼 쿼리를 작성해도 됩니다.
3. 뷰를 사용하는 이유
뷰를 사용하는 이유에 대해 알아보기 전에 DBMS를 사용하는 목적에 대해 알아보도록 하겠습니다.
1) DBMS를 사용하는 목적
DBMS는 데이터 독립성( Data Independence )을 보장하기 위해 사용합니다.

- 외부 스키마
- 사용자 입장에서 보는 논리적인 데이터베이스의 구조를 의미
- 개념 스키마
- 데이터베이스의 전체적인 논리구조, 즉 테이블을 의미
- 내부 스키마
- 데이터가 실제로 저장되는 물리적인 데이터베이스의 구조를 의미
이렇게 3개의 스키마를 일컬어 3-level architecture라고 합니다.
3-level architecture의 장점은 각 스키마 간의 데이터의 독립성이 보장된다는 것입니다.
예를 들어, 데이터가 실제로 저장되는 disk가 변경되어도 개념 스키마, 외부 스키마는 변하지 않습니다.
저장공간을 HDD를 사용하다가 SSD로 바꾼다고 해서 테이블이 바뀌지는 않죠.
2) 뷰를 사용하는 이유
뷰를 사용하는 이유 역시, 독립성을 보장함에 있습니다.
즉, 외부 스키마와 개념 스키마 간의 독립성( 3-level architecture의 logical interface )을 보장하기 위함입니다.
뷰가 독립성을 보장하는 개념은 다음과 같습니다.
- growth
- 뷰에 새로운 Attribute가 추가 되어도 base table에는 영향을 주지 않습니다.
- 반대로 base table에 새로운 Attribute가 추가되어도 뷰에는 영향을 주지 않습니다.
- 따라서 base table과 사용자가 실제로 보는 뷰 간의 데이터 독립성을 보장합니다
서로 독립성을 유지한다는게, 어느쪽이 변경되도 다른쪽이 변경되지 않음을 의미하네.
- restructuring
- 뷰를 통해 base table 중 자주 쓰이는 필드만 골라 작은 테이블로 만들 수 있습니다.
- 즉, 매번 base table에 접근할 필요 없이 뷰에 접근함으로써 연산을 줄일 수 있으며, 필요한 데이터만 보여줌으로써 보안성을 높일 수 있습니다.
JVM
[https://medium.com/@lazysoul/jvm-%EC%9D%B4%EB%9E%80-c142b01571f2]
자바 버추얼 머신은 자바 바이트 코드를 os에 맞게 해석 해주는 역할을 합니다. 자바 컴파일러는 .java 파일을 .class라는 자바 바이트 코드로 변환 시켜 줍니다. 바이트 코드는 기계어가 아니므로 os에서 바로 실행되지 않습니다. 이때 jvm은 os를 위해 바이트 코드를 기계어로 해석해 줍니다. 자바는 jvm의 해석을 거치므로 다른 네이트브 언어에 비해 속도가 느렸지만 JIT 컴파일러를 구현해 극복했습니다.
즉 자바의 가장 큰 장점은 바이트 코드는 JVM위에서 OS 상관없이 실행된다는 점입니다. 자바 파일 하나만 만들면 어느 디바이스든 JVM 위에서 실행이 가능합니다.
JVM은 크게 Class Loader, Runtime Data Areas, Execution Engine 3가지로 구성되어 있습니다.

Class Loader는 런타임 시점에 클래스를 로딩하게 해주며 클래스의 인스턴스를 생성하면 클래스 로더를 통해 메모리에 로드하게 됩니다.
Runtime Data Areas는 JVM이 프로그램을 수행하기 위해 OS로 부터 별도로 할당 받은 메모리 공간을 말합니다. 아래의 5가지 영역으로 나뉩니다.

PC 레지스터는, CPU가 인스트럭션을 수행하는 동안 필요한 정보를 레지스터라 하는 CPU내의 기억장치를 사용한다. 근데 이 이후의 설명은 이해가 안되다...
Java Virtual Machine Stack, 자바 버추얼 머신 스택들은 스레드의 수행정보를 프레임을 통해서 저장하게 된다. 자바 버추얼 머신 스택들은 스레드가 시작될 대 생성되며, 각 스레드 별로 생성되므로 다른 스레드는 접근 할 수 없다. 음 일반적인 메모리 구조에서 스택이랑 비슷한거 같은데
Native Method Stack. 자바 외의 언어로 작성된 네이티브 코드를 위한 스택이다, JNI 자바 네이티브 인터페이스를 통해 호출되는 C/C++등의 코드를 수행하기 위한 스택이다.
네이티브 메소드 호출시 네이티브 메소드 스택에 새로운 스택 프레임을 생성하여 푸쉬한다. 이는 JNI를 이용하여 JVM 내부에 영향을 주지 않기 위함이다.
Method Area, 모든 쓰레드가 공유하는 메모리 영역이다. 메소드 에리어는 클래스, 인터페이스, 메소드, 필드, static 변수등의 바이트 코드 등을 보관한다.
일반적인 코드와 데이터 영역인거 같다.
Heap, 프로그램 상에서 런타임시 동적으로 할당하여 사용하는 영역이다. 클래스를 이용해 객체를 생성하면 Heap에 저장된다.
Execution Engine
Load된 클래스의 바이트 코드를 실행하는 런타임 모듈이 바로 Execution engine입니다. 클래스 로더를 통해 JVM내의 Runtime Data Areas에 배치된 바이트 코드는 Execution Engine에 의해 실행되며, 실행 엔진은 자바 바이트 코드를 명령어 단위로 읽어서 실행합니다.
최초 JVM이 나왔을 당시에는 인터프리터 방식이므로 속도가 느리다는 단점이 있었지만, JIT 컴파일러 방식을 통해 이 점을 보완했습니다. JIT는 바이트 코드를 어셈블러 같은 네이티브 코드로 바꿔서 실행이 빠르지만 역시 변환하는 데는 비용이 발생합니다. 그러므로 JVM은 모든 코드를 JIT 컴파일러 방식으로 실행하지 않고 인터프리터 방식을 사용하다 일정한 기준이 넘어가면 JIT 컴파일러 방식으로 실행합니다.
자바 가비지 콜렉팅
[https://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html] 오라클 문서인듯
가비지 컬렉션은 힙메모리를 보는 과정이다, 어떤 사물이 사용되고 안되는지 식별하고, 사용되지 않는 사물을 제거한다. 사용중인 대상이나, 참조된 사물은 프로그램의 어떤 부분이 해당 대상에 포인터를 유지하고 있다는 의미이다. 사용되지 않거나, 참조되지 않은 객체는, 더이상 내 프로그램의 어느 부분도 참조 하지 않는다는 의미이다. 그러므로 메모리를 다시 요청할 수 있다.
C에서는 메모리의 할당과 해제가 수동적으로 이루어 진다. 기본적인 단계는 아래와 같다.
1단계 : 마킹
가비지 콜렉터가 메모리의 어느 부분이 사용중이고 아닌지 체크한다.

2단계 : 노멀 딜리션
정상적인 삭제 과정은 참조되지 않는 사물들을 제거하고, 참조되는 사물들과 포인터들을 빈공간에 남겨둔다.

2a단계: delition with compacting
더 높은 성능을 위해, 참조되지 않는 사물들을 제거하는 것에 추가로, 우리는 남겨진 참조되는 사물들을 압축할 수 있다. 참조되어지는 사물들을 움직임으로서, 새로운 메모리 할당을 아주 쉽고 빠르게 한다.

why Generational Garbage Collection?
위에서 언급한대로, JVM에서 모든 사물들을 마크하고 압축하는 것은 매우 비효율적이다. 더욱더 많은 사물들을 할당함에 따라, 사물들의 목록은 더욱더 오랜 가비지 컬렉션 시간을 갖고 성장한다. 하지만 경험적인 분석에 으하면 어플리케이션들의 대부분의 사물은 짧은 생존 시간을 갖는다.
볼 수 있듯이, 더 적고 적은 사물들만이 시간에 따라 할당된다. 사실 대부분의 사물들은 아주 짧은 생존 시간을 갖는다.
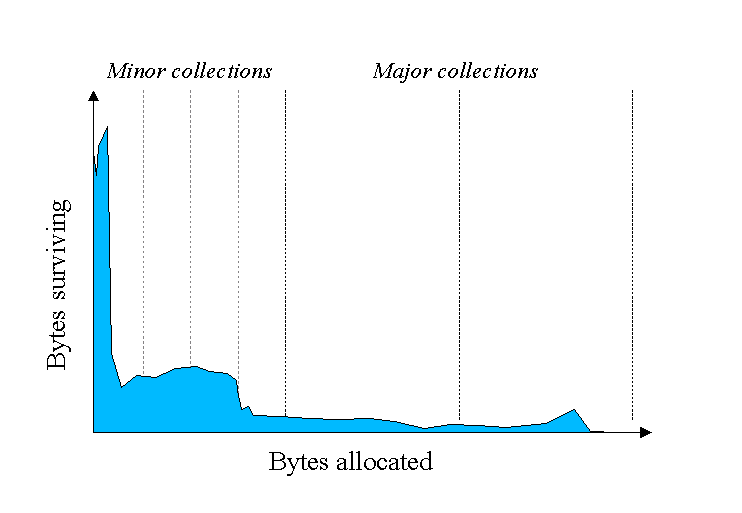
JVM Generations
위에서 설명된 정보는 JVM의 성능을 더욱 향상 시킬 수 있다. 그러므로 힙을 제너레이션들로 분리한다. 힙의 영역은 , young, old, tenured, permanent Generation으로 나뉜다.

Young Generation은 새로운 객체들이 할당 되고 늙어 가는 곳이다. 영 제너레이션이 꽉차면 마이넌 가비지 콜렉션이 수행된다. 마이너 콜렉션들은 높은 사망률을(motality) 가정하여 최적화된다. 영 제너레이션은 죽은 사물들로 빠르게 수집된다. 몇몇 생존 사물들은 늙고 결과적으로 old generation으로 이동한다.
Stop the World Event - 모든 마이너 가비지 콜렉션들은 세상아 멈춰라 사건들이다. 즉 모든 어플리케이션 스레드들이 작업이 완료되기 전까지 멈춘다. 마이너 가비지 콜렉션들은 항상 세상아 멈춰라 사건들이다.
Old Generation은 오래 생존한 사물들을 저장하기 위해 사용된다. 전형적으로, 영 제너레이션 사물들이 나이가 차면, old 제너레이션으로 옮겨 진다. 결국에는 old 제너레이션은 수집되어야 한다. 이러한 이벤트는 major garbage collection이라 한다.
메이저 가비지 콜렉션 또한 세상아 멈춰라 사거들이다. 종종 메이저 콜렉션은 훨씬 느리다 왜냐하면 살아있는 사물들을 포함하기 때문이다. 그러므로 반응적인 어플리케이션들을 위해서는, 메이저 가비지 콜렉션들을 최소화해야 한다. 그러므로 말하자면, 메이저 가비지 콜렉션을 위한 세상아 멈춰라의 길이는 old generation 공간을 위해 사용되는 가비지 콜렉터에 영향을 받는다. 즉 올드 제너레이션에서의 가비지 콜렉션의 시간이 가장 길어서, 여기서의 시간이 결국 전체 가비지 콜렉션 시간이랑 관련 있다는 말 같다.
permanent generation은 JVM이 어플리케이션에서 사용하는 클래스들과 메소드들을 설명하기 위한 메타데이터들을 저장한다. 펄메이넌트 영역은 어플리케이션이 런타임에 사용하는 클래스들에 기반하여 채워진다.(populated). 추가로 java SE 라이브러리 클래스들 그리고 메소드들을 저장할 수 있다.
클래스들도 콜렉티드 될 수 있다. JVM이 그 클래스들이 더이상 필요없다 생각하고 다른 클래스들이 그 공간을 필요로 한다면. 영구 세대는 full garbage collection에 포함된다.
이하는 Generation Garbage Collection Process인데 너무 길어서 못정리 하겠다 지금은;;
[https://lyb1495.tistory.com/3] 여기 한글 본이 있긴한데 그림이 없어서; 밑에랑 같이 보자.
Now that you understand why the heap is separted into different generations, it is time to look at how exactly these spaces interact. The pictures that follow walks through the object allocation and aging process in the JVM.
First, any new objects are allocated to the eden space. Both survivor spaces start out empty.
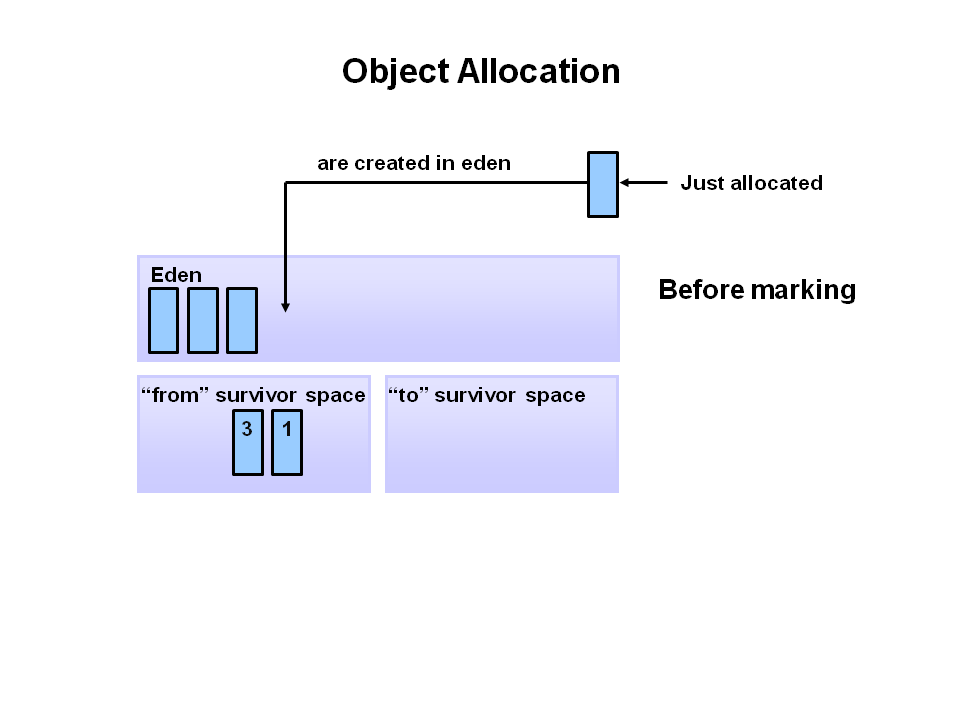
When the eden space fills up, a minor garbage collection is triggered.
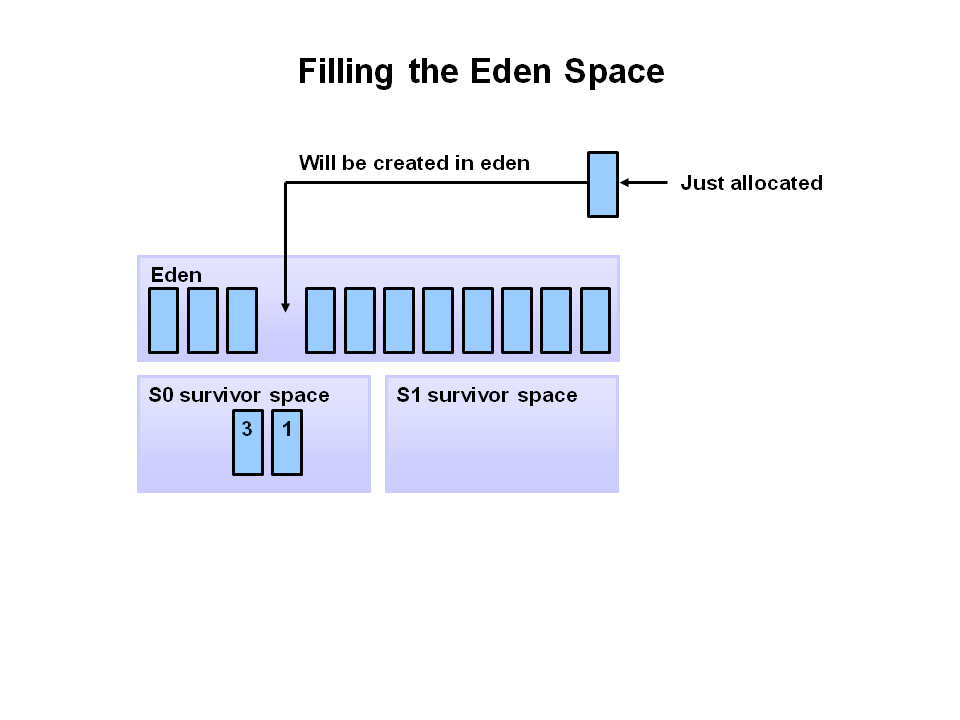
Referenced objects are moved to the first survivor space. Unreferenced objects are deleted when the eden space is cleared.

At the next minor GC, the same thing happens for the eden space. Unreferenced objects are deleted and referenced objects are moved to a survivor space. However, in this case, they are moved to the second survivor space (S1). In addition, objects from the last minor GC on the first survivor space (S0) have their age incremented and get moved to S1. Once all surviving objects have been moved to S1, both S0 and eden are cleared. Notice we now have differently aged object in the survivor space.
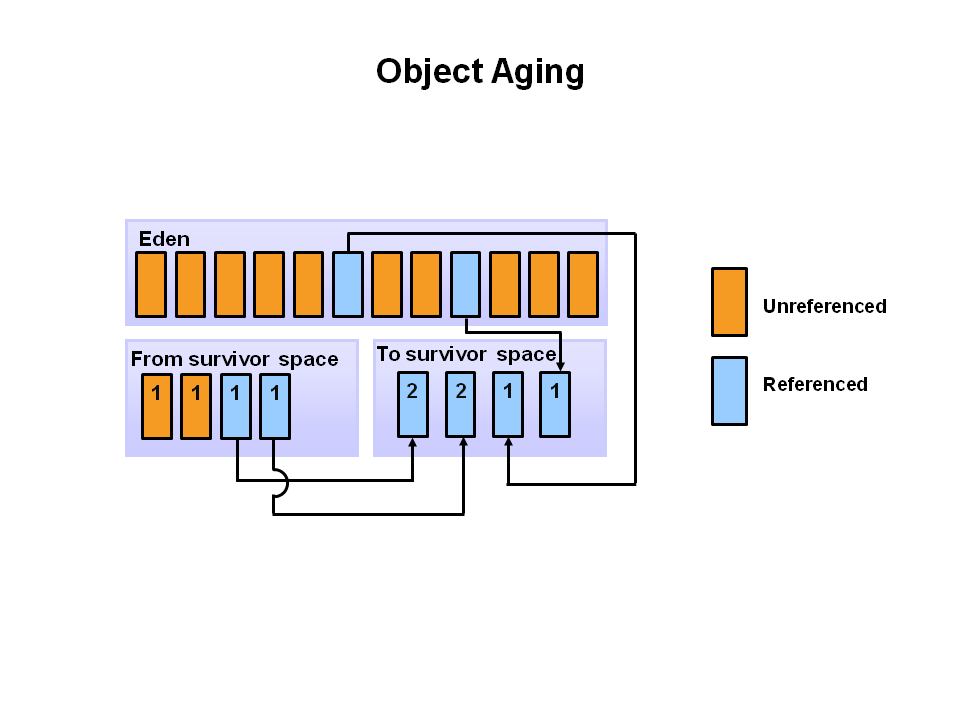
At the next minor GC, the same process repeats. However this time the survivor spaces switch. Referenced objects are moved to S0. Surviving objects are aged. Eden and S1 are cleared.

This slide demonstrates promotion. After a minor GC, when aged objects reach a certain age threshold (8 in this example) they are promoted from young generation to old generation.

As minor GCs continue to occure objects will continue to be promoted to the old generation space.

So that pretty much covers the entire process with the young generation. Eventually, a major GC will be performed on the old generation which cleans up and compacts that space.

'취업,면접 대비 > 면접 대비 문제' 카테고리의 다른 글
| <면접 대비> 네트워크 면접 대비 3편 - DNS,네트워크 7계층 (0) | 2020.04.06 |
|---|---|
| <면접 대비> : 퀵소트vs힙소트, 스택 vs 힙 (0) | 2020.03.03 |
| 1탄 : thread vs process (0) | 2020.02.27 |